Knowledge
Built-in RAG knowledge — Knowledge Bases, connectors, and retrieval architecture
A Knowledge Base is a set of connectors that index your data for retrieval. Connectors pull from tools such as Jira, Confluence, GitHub, Notion, SharePoint, Google Drive, and Salesforce. An agent assigned a Knowledge Base can query that data to answer questions. The full RAG stack (chunking, embedding, hybrid search, reranking) runs inside Archestra — no external vector database or separate retrieval service required.
Enterprise feature (team-scoped access control) — see the Pricing Model.
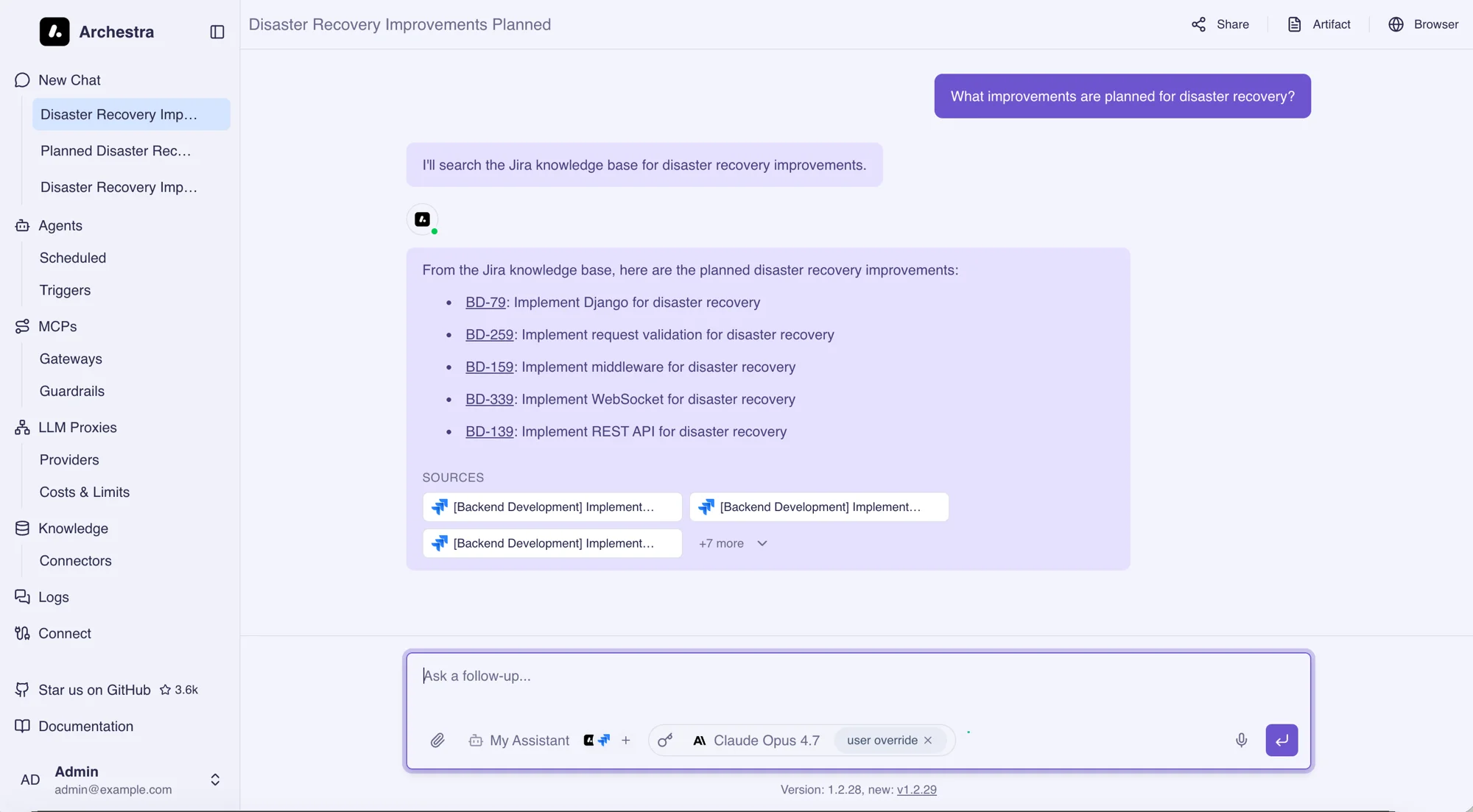
Configuration
Open Settings > Knowledge. Both an embedding and a reranking model must be set before Knowledge Bases can be used.
Embedding Configuration
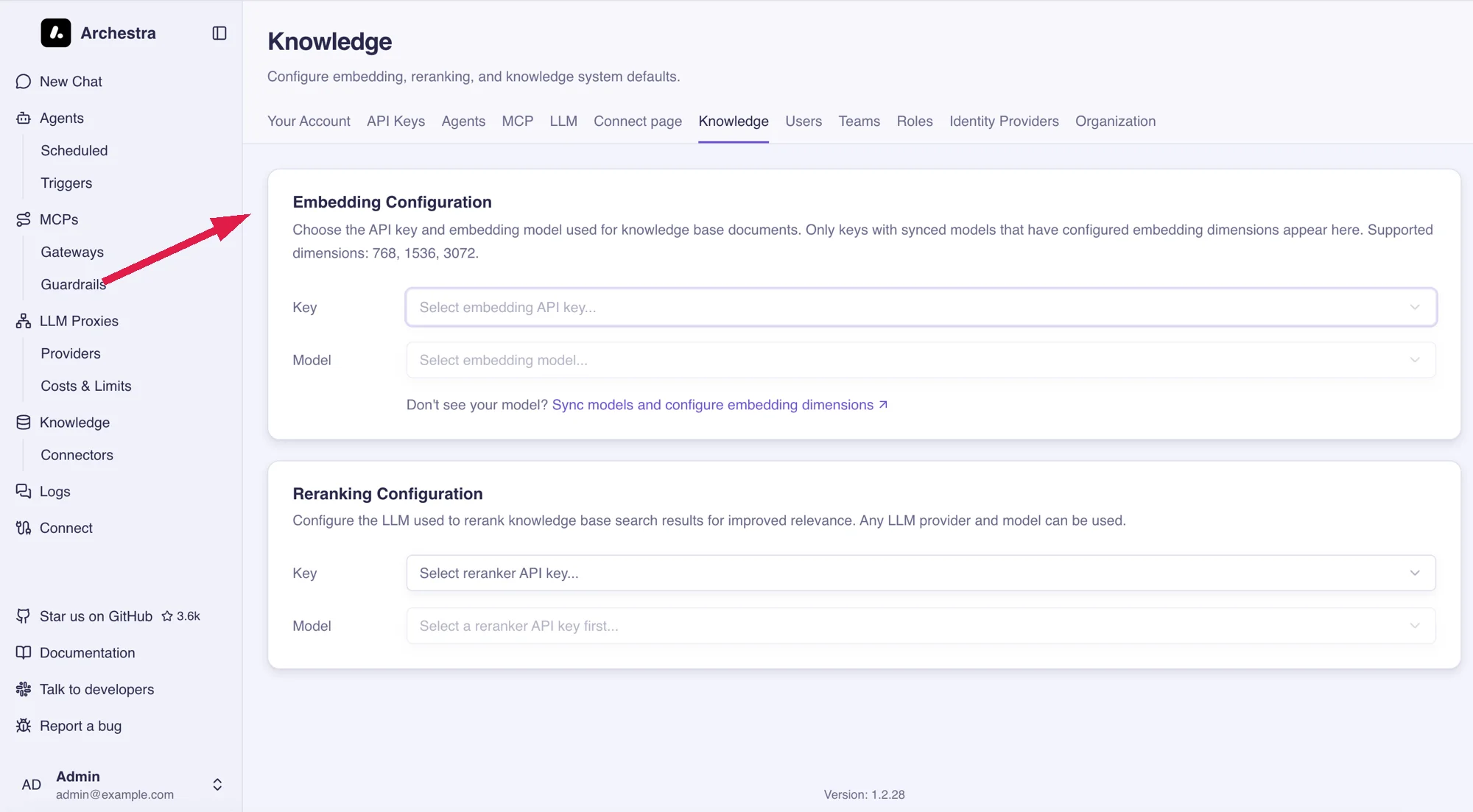
Pick the API key and embedding model. The embedding model vectorizes ingested documents so they can be queried semantically. The same model is used for both indexing and querying, which is why it is locked once saved.
- Key — only keys whose synced models have configured embedding dimensions appear in this list. If yours is missing, go to LLM Providers > Models, sync the provider, and set the dimensions for the embedding model. Supported dimensions: 384, 768, 1024, 1536, 3072.
- Model — any embedding-capable model exposed by the selected key.
To change the embedding model, click Drop to clear the existing index — every document will need to be re-embedded on the next connector sync. The lock also applies in LLM Providers > Models: the configured model's embedding dimensions cannot be edited until the configuration is dropped.
Reranking Configuration
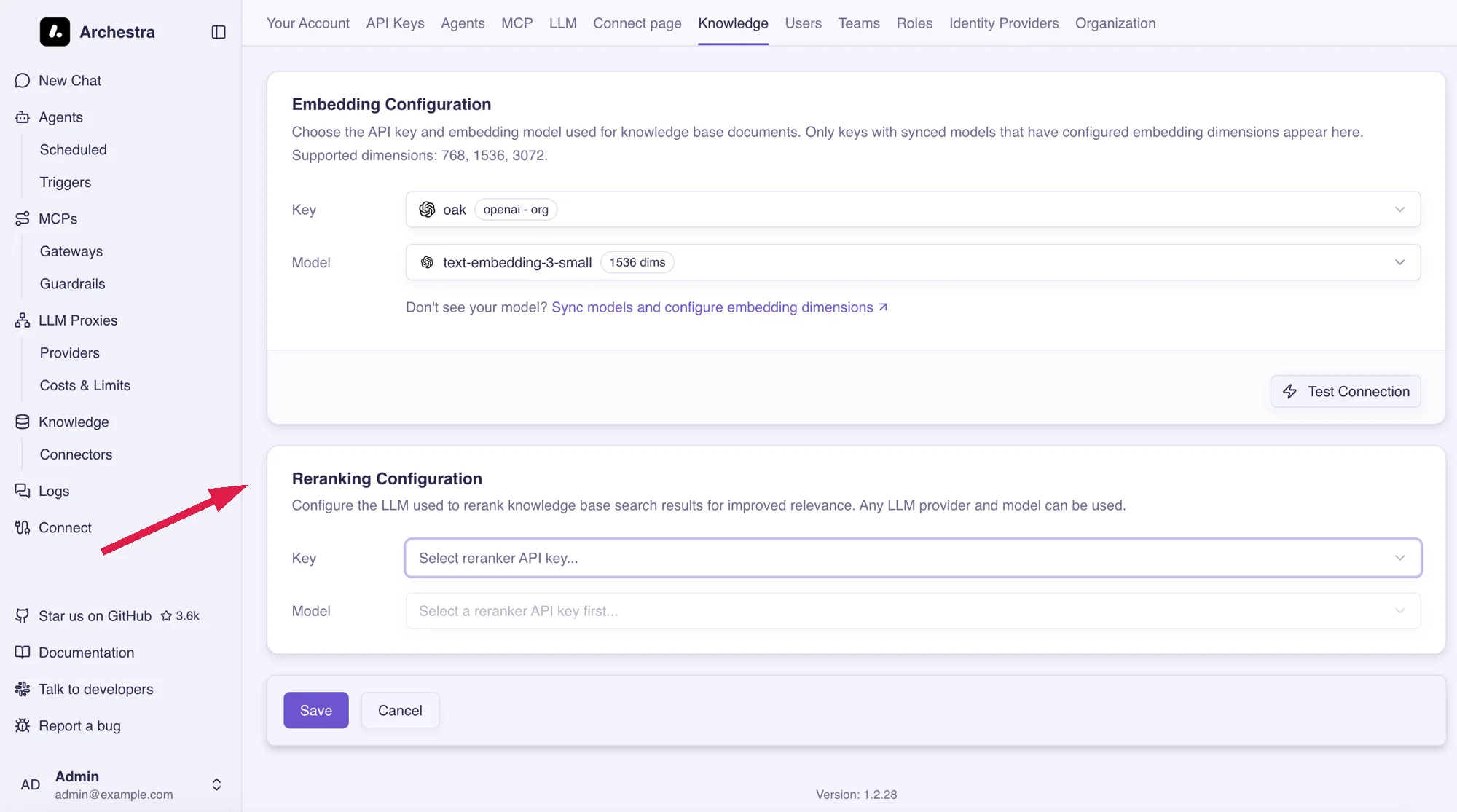
Pick the LLM that scores and reorders search results by relevance.
- Key — any LLM provider key.
- Model — any chat model from that provider.
Creating a Knowledge Base
A Knowledge Base is a set of connectors. Create one from the Knowledge page and assign connectors to get data from. The same Knowledge Base can be reused across multiple agents and MCP Gateways.
Assigning to an Agent
An agent — or an MCP Gateway — reaches knowledge through the Tools & Knowledge Sources setting in its dialog, which has two modes:
- Auto — the agent can search every Knowledge Base and connector the chatting user can access, within the agent's environment. Nothing is assigned; the reachable set follows each user's own visibility.
- Custom — the agent searches only the Knowledge Bases and connectors you assign to it. Pick them under Knowledge Sources; the picker stays disabled until an embedding and reranking model are set (see Configuration).
Either mode is still filtered by the chatting user's own visibility, so an agent never surfaces a source the user could not read themselves. Once the agent has at least one reachable source, it gains a query_knowledge_sources tool that searches across them and returns the most relevant documents.
The output of query_knowledge_sources is treated as sensitive by default, which can impact the ability to use subsequent tools. See Archestra MCP Server, and AI Tool Guardrails, for more details.
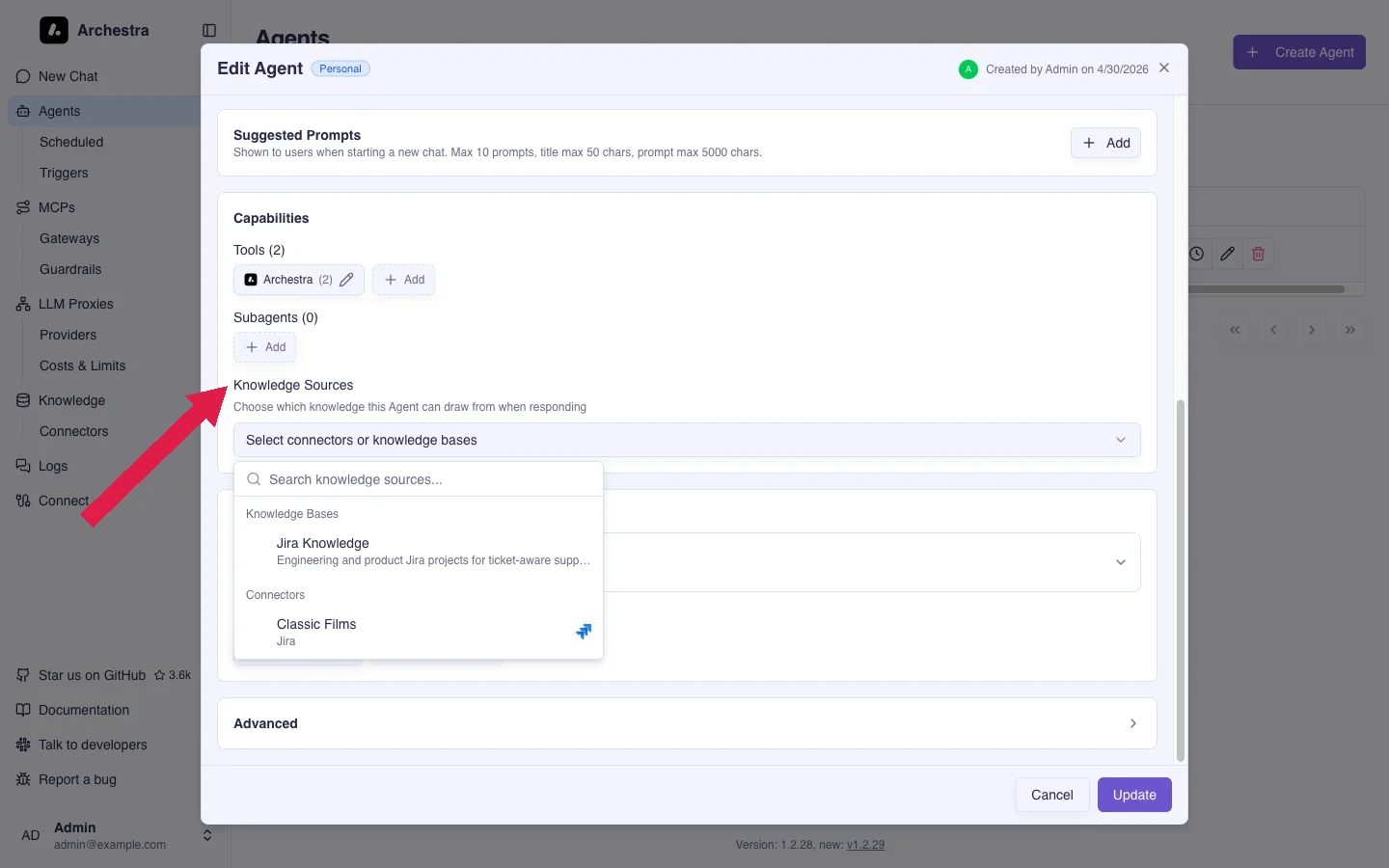
Connectors pull data from external tools into Knowledge Bases. A connector can be assigned to multiple Knowledge Bases.
Visibility
Each connector has a visibility setting that determines which users can retrieve its data when an agent calls query_knowledge_sources. Connectors and Knowledge Bases are filtered by visibility throughout the UI: users only see sources they have access to, and only those can be assigned to agents and MCP Gateways.
| Mode | Behavior |
|---|---|
| Org-wide | All documents accessible to every user in the organization. |
| Team-scoped | Documents accessible only to members of the assigned teams. |
| Auto-sync permissions | Per-document ACLs synced from the source system, so each user sees only what they can see upstream. See Auto-Sync Permissions. |
Users with the knowledgeSource:admin permission can view and query every connector regardless of visibility.
Auto-sync connectors are gated by the dedicated knowledgeSourceAutoSync permissions. They control who can create, update, and see these connectors. By default only the Admin role has them; grant them to other users through a custom role. Users without them still query the connector's documents — their results follow the synced ACLs.
Enterprise feature (team-scoped visibility and auto-synced ACLs) — see the Pricing Model.
Auto-Sync Permissions
Beta feature — off by default. Set
ARCHESTRA_KNOWLEDGE_BASE_AUTO_SYNC_PERMISSIONS_ENABLED=true(or theARCHESTRA_BETAmaster switch) to show the visibility option and its Users and Groups tabs. See Deployment.
Auto-sync permissions mirrors the data source system's access control into Archestra. When a user queries the knowledge base, they get back only the content they are allowed to see in the source system. A user with the knowledgeSource:admin role bypasses the ACL and sees everything.
Auto-sync permissions works with the connectors marked Supported below. The others do not support it yet.
| Connector | Auto-sync permissions |
|---|---|
| Confluence | Supported |
| GitHub | Supported |
| Jira | Supported |
| Google Drive | Planned |
| Salesforce | Planned |
| SharePoint | Planned |
| Asana | Not supported |
| Dropbox | Not supported |
| GitLab | Not supported |
| Linear | Not supported |
| Notion | Not supported |
| OneDrive | Not supported |
| Outline | Not supported |
| Perforce | Not supported |
| ServiceNow | Not supported |
| Web Crawler | Not supported |
Upstream email visibility. Each source hides emails behind its own rule, and a credential that can't see them produces a snapshot full of unresolvable (fail-closed) members:
- Jira and Confluence Cloud only return another user's email through the product REST API when that user's Atlassian profile has email visibility set to "Anyone". Add an Atlassian organization admin API key to the connector credentials to read managed accounts' emails.
- GitHub only exposes an email the user has made public on their profile; no token scope reveals a private email.
Permission-read access. The credential must also be able to read the source's permission settings — Jira permission schemes, Confluence space permissions, GitHub repository collaborators. A credential that cannot read them hides that project or space from everyone, because Archestra never assumes an audience it could not verify. Each sync run reports how many it could not read, so a project nobody can find is easy to tell apart from a project nobody is granted.
Manual user assignment. When an account's email stays hidden, assign it to an Archestra user from the Users tab.
Atlassian Organization Admin API Key
An organization admin API key reads managed accounts' emails through the Atlassian admin APIs. Add it to a Jira or Confluence connector, and permission sync resolves members whose profile email visibility is not "Anyone".
Create the key in Atlassian administration under Settings → API keys:
- Select Create API key and name it.
- Leave the key without scopes. Permission sync calls the classic admin APIs, which scopes do not cover.
- Copy the key into the connector's Organization admin API key field.
The API token stays required. Atlassian does not accept admin API keys on the Jira and Confluence APIs.
Supported Connectors
Archestra ships with these built-in connector types.
Jira
Sync issues and discussions from Atlassian Jira.
Indexed: issue descriptions, comments, and metadata from Jira Cloud or Server.
Authentication: an Atlassian account email and an API token. For auto-sync permissions on Cloud, also add an organization admin API key.
| Field | Description |
|---|---|
| Base URL | Your Jira instance URL (e.g., https://your-domain.atlassian.net) |
| Cloud Instance | Toggle on for Jira Cloud, off for Jira Server/Data Center |
| Project Keys | Comma-separated project keys to include (optional) |
| JQL Query | Custom JQL to filter issues (optional) |
| Comment Email Blacklist | Comma-separated emails whose comments are excluded (optional) |
| Labels to Skip | Comma-separated issue labels to exclude (optional) |
Confluence
Sync wiki pages from Atlassian Confluence.
Indexed: pages from Confluence Cloud or Server.
Authentication: the same Atlassian email and API token used for Jira, with the same optional organization admin API key for auto-sync permissions.
| Field | Description |
|---|---|
| URL | Your Confluence instance URL (e.g., https://your-domain.atlassian.net/wiki) |
| Cloud Instance | Toggle on for Confluence Cloud, off for Server/Data Center |
| Space Keys | Comma-separated space keys to sync (optional) |
| Page IDs | Comma-separated specific page IDs to sync (optional) |
| CQL Query | Custom CQL to filter content (optional) |
| Labels to Skip | Comma-separated labels to exclude (optional) |
| Batch Size | Pages per batch (default: 50) |
GitHub
Sync issues, pull request discussions, and repository files from GitHub.
Indexed: issues, pull requests, comments, and selected text files from GitHub.com or GitHub Enterprise Server. Repository file indexing defaults to Markdown and YAML files.
Authentication: a personal access token or a GitHub App. GitHub App credentials (App ID, installation ID, and private key) are stored once as an organization-level configuration under Settings -> GitHub; the connector references a saved configuration instead of holding its own credentials, so one App can back many connectors and skill imports.
| Field | Description |
|---|---|
| GitHub API URL | API endpoint (e.g., https://api.github.com for GitHub.com, or your GHE API URL) |
| Owner | GitHub organization or username that owns the repositories |
| Authentication Method | Personal access token or GitHub App |
| GitHub App Configuration | Saved configuration to authenticate with when using GitHub App auth (managed in Settings -> GitHub) |
| Repositories | Comma-separated repository names to sync (optional -- leave blank to sync all org repositories) |
| Include Issues | Toggle to sync issues and their comments (default: on) |
| Include Pull Requests | Toggle to sync pull requests and their comments (default: on) |
| Include Repository Files | Toggle to sync repository files (default: off) |
| File Types | Comma-separated file extensions to index when repository files are enabled (defaults to .md, .mdx, .yaml, .yml) |
| Labels to Skip | Comma-separated labels to exclude (optional) |
GitLab
Sync issues and merge request discussions from GitLab.
Indexed: issues, merge requests, and their comments from GitLab.com or self-hosted GitLab instances. System-generated notes (assignment changes, label updates, etc.) are filtered out.
Authentication: a personal access token.
| Field | Description |
|---|---|
| GitLab URL | Instance URL (e.g., https://gitlab.com or your self-hosted URL) |
| Group | GitLab group ID or path to scope project discovery (optional) |
| Project IDs | Comma-separated specific project IDs to sync (optional -- leave blank to sync all) |
| Include Issues | Toggle to sync issues and their comments (default: on) |
| Include Merge Requests | Toggle to sync merge requests and their comments (default: on) |
| Labels to Skip | Comma-separated labels to exclude (optional) |
Asana
Sync tasks and discussions from Asana projects.
Indexed: tasks and their user comments from selected Asana projects.
Authentication: a personal access token.
| Field | Description |
|---|---|
| Workspace GID | Your Asana workspace GID (found in the URL when viewing your workspace) |
| Project GIDs | Comma-separated project GIDs to sync (optional -- leave blank to sync all workspace projects) |
| Tags to Skip | Comma-separated tag names to exclude (optional) |
ServiceNow
Sync ITSM records from a ServiceNow instance.
Indexed: incidents, change requests, change tasks, problems, and business applications. Incidents are enabled by default; the rest are opt-in.
Authentication: basic auth (username + password) or an OAuth bearer token. For basic auth, put the username in the Email field and the password in the API Token field. For OAuth, leave Email empty and put the bearer token in the API Token field.
| Field | Description |
|---|---|
| Instance URL | Your ServiceNow instance URL (e.g., https://your-instance.service-now.com) |
| Include Incidents | Sync incidents from the incident table (default: on) |
| Include Changes | Sync change requests from the change_request table (default: off) |
| Include Change Tasks | Sync change tasks from the change_task table (default: off) |
| Include Problems | Sync problems from the problem table (default: off) |
| Include Business Applications | Sync business applications from the cmdb_ci_business_app CMDB table (default: off) |
| States | Comma-separated state values to filter by (e.g. 1, 2). Applies to incidents, changes, change tasks, and problems (optional) |
| Assignment Groups | Comma-separated assignment group sys_ids to filter by. Does not apply to business applications (optional) |
| Batch Size | Records per batch (default: 50) |
Notion
Sync pages and databases from a Notion workspace.
Indexed: pages from a Notion workspace.
Authentication: a Notion integration token (starts with secret_). Create an internal integration in your workspace and share the relevant pages or databases with it.
| Field | Description |
|---|---|
| Database IDs | Comma-separated Notion database IDs to sync (optional -- leave blank to sync all accessible pages) |
| Page IDs | Comma-separated specific Notion page IDs to sync (optional -- takes precedence over Database IDs) |
SharePoint
Sync documents and site pages from SharePoint Online.
Indexed: documents and site pages from SharePoint Online. Supported document types include .txt, .md, .csv, .json, .xml, .html, .htm, .yaml, .log, .docx, .pdf, and .pptx. When a multimodal embedding model is configured, image files (.jpg, .jpeg, .png, .gif, .webp) up to 4 MB are also indexed.
Authentication: an Azure AD app registration with client credentials (OAuth2). The app needs the Sites.Read.All application permission on Microsoft Graph, with admin consent granted.
| Field | Description |
|---|---|
| Tenant ID | Your Azure AD (Entra ID) tenant ID or domain |
| Site URL | Your SharePoint site URL (e.g., https://your-tenant.sharepoint.com/sites/your-site) |
| Client ID | Azure AD app registration Application (client) ID |
| Client Secret | Azure AD app registration client secret value |
| Drive IDs | Comma-separated document library IDs to sync (optional -- leave blank to sync all site libraries) |
| Folder Path | Restrict sync to a specific folder path within each drive (optional) |
| Recursive | Traverse subfolders within each drive or Folder Path (default: on) |
| Include Pages | Toggle to sync site pages and their web part content (default: on) |
Where to find each value:
- Tenant ID — Microsoft Entra ID > App registrations >
> Overview > Directory (tenant) ID . - Client ID — Application (client) ID on the same page.
- Client Secret — the secret Value from Certificates & secrets (not the secret ID).
- Site URL — the exact SharePoint site web URL, not the display name.
OneDrive
Ingests files from OneDrive for Business (personal drives of specified users) via the Microsoft Graph API. Text is extracted from .txt, .md, .csv, .json, .xml, .html, .htm, .yaml, .log files, as well as .docx, .pdf, and .pptx documents. When a multimodal embedding model is configured (e.g., gemini-embedding-2-preview), image files (.jpg, .jpeg, .png, .gif, .webp) up to 4 MB are also ingested and embedded directly.
| Field | Description |
|---|---|
| Tenant ID | Your Azure AD (Entra ID) tenant ID or domain (e.g., xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx) |
| Client ID | Azure AD app registration Application (client) ID |
| Client Secret | Azure AD app registration client secret value |
| User IDs | Comma-separated list of user principal names or object IDs whose OneDrive to sync (e.g., user@company.com) |
| Folder ID | Restrict sync to a specific OneDrive folder (optional -- find the ID from the Graph API or a drive item URL) |
| File Types | Comma-separated file extensions to include, e.g. .pdf, .docx (optional -- leave blank for all supported types) |
| Recursive | Traverse subfolders within each user's drive (default: on) |
Authentication uses an Azure AD app registration with client credentials (OAuth2). The app registration requires the Files.Read.All application permission on Microsoft Graph, and admin consent must be granted.
To configure the connector:
Tenant IDcomes from Microsoft Entra ID > App registrations >> Overview > Directory (tenant) ID Client IDcomes from Application (client) ID on the same pageClient Secretis the secret Value from Certificates & secrets, not the secret IDUser IDsshould be user principal names (UPNs, e.g.user@company.com) or Azure AD object IDs for the users whose drives you want to sync
Incremental sync uses the lastModifiedDateTime field to fetch only items modified since the last run.
Known Limitations
- Only OneDrive for Business (work/school accounts) is supported. Consumer OneDrive is not supported.
- Syncs the personal drive (
/drive) of each specified user; shared libraries are not traversed.
Google Drive
Sync files from Google Drive (My Drive and Shared Drives).
Indexed: files from My Drive and Shared Drives. Supported document types include .txt, .md, .csv, .json, .xml, .html, .htm, .yaml, .log, .docx, .pdf, and .pptx. Google Workspace files (Docs, Sheets, Slides) are also indexed. When a multimodal embedding model is configured, image files (.jpg, .jpeg, .png, .gif, .webp) are indexed too. Files larger than 10 MB are skipped.
Authentication: either a service account JSON key (recommended) or a short-lived OAuth2 access token with the drive.readonly scope. For a service account: create one in the Google Cloud Console, enable the Google Drive API, download the JSON key, and share the target folders or drives with the service account email. Paste the full JSON contents (or the bearer token) into the Service Account Key / OAuth Token field.
| Field | Description |
|---|---|
| Drive IDs | Comma-separated shared drive IDs to sync (optional -- providing Drive IDs automatically enables shared-drive API access; leave blank to sync from My Drive) |
| Folder ID | Restrict sync to a specific folder (optional -- find the ID in the folder's Google Drive URL) |
| File Types | Comma-separated file extensions to include, e.g. .pdf, .docx (optional -- leave blank for all) |
| Recursive Traversal | Sync files from all nested subfolders when a Folder ID is set (default: on) |
Dropbox
Sync text and source files from a Dropbox account or team folder.
Indexed: text-based files from a Dropbox account or team folder. Supported extensions: .md, .txt, .ts, .js, .py, .json, .yaml, .yml, .html, .css, .csv, .xml, .sh, .toml, .ini, .conf.
Authentication: a Dropbox access token. Generate one from the Dropbox App Console by creating an app with the files.content.read permission.
| Field | Description |
|---|---|
| Root Path | Folder path to scope the sync (e.g., /team-docs). Leave blank to sync the entire account. |
| File Types | Comma-separated file extensions to include (e.g., .md, .txt). Leave blank to sync all supported types. |
Linear
Sync issues, projects, and cycles from a Linear workspace.
Indexed: issues by default, with optional projects (and recent updates) and cycles.
Authentication: a Linear personal API key. Create one under Settings > Security & access > Personal API keys in Linear, then paste it into the connector's Personal Access Token field.
| Field | Description |
|---|---|
| Linear API URL | GraphQL API base URL (default: https://api.linear.app) |
| Team IDs | Comma-separated team IDs to scope sync (optional) |
| Project IDs | Comma-separated project IDs to scope sync (optional) |
| Issue States | Comma-separated issue state names (e.g. Todo, In Progress, Done) |
| Include Comments | Include issue comments in indexed content (default: on) |
| Include Projects | Sync projects and recent project updates as documents (default: off) |
| Include Cycles | Sync cycles as documents (default: off) |
| Batch Size | Items fetched per request (optional, defaults to connector implementation) |
Outline
Sync published documents from an Outline workspace.
Indexed: published documents. Both Outline cloud (https://app.getoutline.com) and self-hosted instances are supported.
Authentication: an Outline API key. Create one under Settings > API & Apps in your Outline workspace. Only documents the key has access to are synced.
| Field | Description |
|---|---|
| Instance URL | The base URL of your Outline workspace (e.g. https://app.getoutline.com or your self-hosted URL). |
| API Key | Your Outline API key (starts with ol_api_). |
| Collection IDs | Optional comma-separated list of collection IDs to sync. Leave blank to sync all accessible documents. |
Salesforce
Sync CRM records from a Salesforce org.
Indexed: CRM records from a Salesforce org. By default the connector syncs Account, Contact, Opportunity, and Case. You can list other object API names in the Objects field, or use Advanced Object Config JSON to pick exact fields and associations per object.
Authentication: a Salesforce username, password, and security token. The password field must contain the password directly concatenated with the security token (no separator). To get the token: log in to Salesforce, click your User Avatar > Settings, then go to My Personal Information > Reset My Security Token and check your email.
| Field | Description |
|---|---|
| Login URL | Salesforce login endpoint (default: https://login.salesforce.com; use https://test.salesforce.com for sandbox orgs) |
Your Salesforce username (e.g., user@company.com) | |
| Password + Security Token | Your Salesforce password concatenated with your security token (e.g., MyPassword123XXYYZZ) |
| Objects | Comma-separated Salesforce object API names to sync (e.g., Account, Contact, Opportunity, Case). Leave blank for the defaults. |
| Advanced Object Config JSON | Optional JSON for precise field and association control. Overrides the Objects field when provided. |
Example advanced config:
{
"Lead": {
"fields": ["FirstName", "LastName", "Company", "Email"],
"associations": { "Account": ["Name"] }
},
"Case": {
"fields": ["Subject", "Status", "Priority", "Description"]
}
}
Id, Name, and LastModifiedDate are always included automatically.
Web Crawler
Crawl static HTML pages from a documentation site or public web property.
Indexed: same-host HTML pages discovered from the start URL. The crawler extracts page text, removes common navigation and layout elements, and stores each page with its canonical URL when one is present.
Authentication: none in the initial version. The crawler only fetches pages reachable over HTTP(S).
Private and internal network addresses are blocked. Start URLs and discovered pages cannot resolve to loopback, link-local, RFC 1918 private ranges, cloud metadata endpoints, or other reserved address ranges. Hosts are checked before each fetch, but DNS records can change between validation and the final network request.
If the start URL is the site root, such as https://example.com/, and no include path prefixes are configured, the crawler can discover any same-host page within the configured depth and page limits.
| Field | Description |
|---|---|
| Start URL | First page to crawl. Crawling stays on the same host. |
| Include Path Prefixes | Comma-separated paths to crawl, such as /docs/ or /guides/. Defaults to the start URL path. |
| Exclude Path Patterns | Comma-separated regular expressions matched against path and query, such as /search or /archive/.*. |
| Content Selector | CSS selector for the page content root. Leave blank to use default document selectors. |
| Exclude Selectors | Comma-separated CSS selectors to remove before extracting text, such as .sidebar or .toc. |
| Max Pages | Maximum pages to crawl in one sync (default: 250). |
| Max Depth | Maximum link depth from the start URL (default: 3). |
| Batch Size | Documents yielded per sync batch (default: 25). |
| Request Delay | Optional delay between requests, in milliseconds. |
| User Agent | Optional custom User-Agent header for crawl requests. |
Perforce (Helix Core)
Sync text files from Perforce Helix Core depot paths.
Indexed: files matching the configured extensions (defaults to .md, .yaml, .yml) under the configured depot paths, at their latest submitted revision. Files with non-text Perforce filetypes (binary, symlink, etc.) and files larger than 2 MB are skipped regardless of the extension list, so broadening the extensions (e.g. adding .txt, .json, or .xml) is safe even in depots that mix documentation with binary assets. Optional exclude paths carve subtrees (e.g. generated or vendored directories) out of the synced depot paths.
Authentication: a Perforce username with a login ticket, sent as HTTP basic authentication. The ticket must be valid for all hosts — generate it with p4 login -a -p. For long-lived access, use a service account whose group has an unlimited ticket timeout. The account needs read access to the configured depot paths.
The connector talks to the P4 REST API, served by the built-in P4 web server. An administrator must start the web server on the P4 Server (p4 webserver start -p <port>; it serves HTTPS automatically when the server has an SSL certificate configured). The REST API is a Perforce Technology Preview feature (introduced with P4 Server 2025.2), so its behavior may change between server releases. No p4 client binary and no client workspace (P4CLIENT) are required — files are listed and read directly in depot syntax over HTTP. For servers with self-signed certificates, provide the CA to the backend via standard Node.js trust configuration (NODE_EXTRA_CA_CERTS).
Incremental syncs are driven by submitted changelist numbers: after the initial sync, only files changed since the last synced changelist are re-indexed. File deletions are not propagated on incremental syncs; use Force re-sync to rebuild the index after large depot restructurings.
Each depot path and extension combination is listed in its own REST API request. On very large depots, server maxresults limits or per-request response bounds can reject a listing; configure narrower depot paths if the initial sync fails while listing files.
| Field | Description |
|---|---|
| Server URL | Base URL of the P4 REST API served by the P4 web server (e.g., https://perforce.example.com:8080) |
| Depot Paths | Comma-separated depot paths to sync recursively, in depot syntax (e.g., //depot/docs) |
| Username | The Perforce user (P4USER) the connector authenticates as |
| Login Ticket | An all-hosts ticket from p4 login -a -p |
| File Types | Comma-separated file extensions to index (defaults to .md, .yaml, .yml) |
| Exclude Paths | Optional comma-separated depot paths skipped within the synced paths (e.g., //depot/docs/generated) |
Environments
A connector can be assigned a deployment environment. Only agents and gateways in the same environment can use its knowledge — a "dev" agent cannot query a "prod" connector. Unassigned connectors belong to the Default environment. See Environments.
Adding New Connector Types
See Adding Knowledge Connectors for a developer guide on implementing new connector types.
Architecture
The RAG stack runs entirely within PostgreSQL — no external vector database. See Deployment — Knowledge Base Configuration for the full configuration reference.
Ingestion. Connectors run on a cron schedule; documents are chunked and embedded into PostgreSQL with pgvector.
Querying. The agent's query is embedded, then vector and optional full-text search run in parallel. Results are fused, reranked, and ACL-filtered before being returned.